
 We analyzed and optimized the workflow for extracting parton distribution functions from high-energy electron-proton scattering data. Profiling showed 93% of single-core time was spent on phase-space density calculations, with 78% idle time in parallel runs due to load imbalance. Optimizing the DGLAP evolution solver and using a hybrid dynamic-static scheduling strategy cut idle time by 62%, delivered a 2.46x speedup per node, and improved strong scaling. Power management features like AMD Turbo Core and RAPL limited scalability, highlighting the need for thorough intra-node performance testing.
We analyzed and optimized the workflow for extracting parton distribution functions from high-energy electron-proton scattering data. Profiling showed 93% of single-core time was spent on phase-space density calculations, with 78% idle time in parallel runs due to load imbalance. Optimizing the DGLAP evolution solver and using a hybrid dynamic-static scheduling strategy cut idle time by 62%, delivered a 2.46x speedup per node, and improved strong scaling. Power management features like AMD Turbo Core and RAPL limited scalability, highlighting the need for thorough intra-node performance testing.
Background
The inference of quantum correlation functions (QCFs) from high-energy electron-proton scattering data using simulation-based inference and stochastic optimization requires the computational capabilities of modern exascale supercomputers, such as Aurora at Argonne National Laboratory. Given the considerable energy consumption and operational costs of these systems, applications must demonstrate efficient use of computational resources to achieve an optimal cost-performance balance. Before deploying large-scale production runs on these machines, an analysis of computational performance and parallel efficiency is necessary. This work presents such an analysis and highlights performance engineering practices aimed at reducing computational costs and improving the overall efficiency of a QCF inference workflow.
Performance Analysis
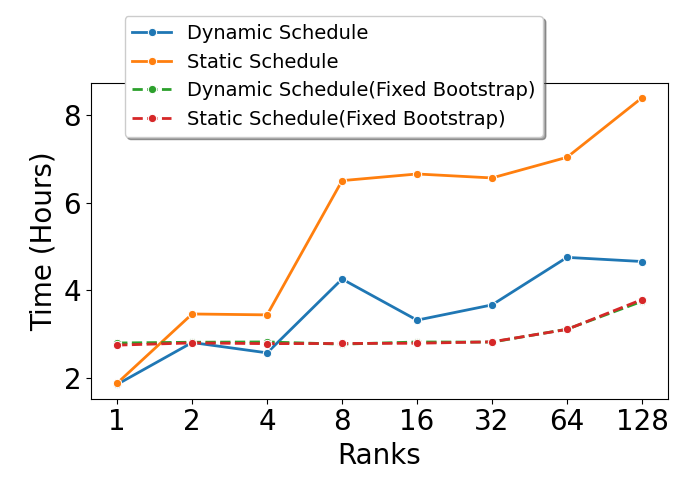
Our analysis found that 93% of runtime was consumed by solving DGLAP (Dokshitzer–Gribov–Lipatov–Altarelli–Parisi) integro-differential equations. In intra-node CPU parallel runs, 78% of core hours were lost to load imbalance, reducing strong scaling efficiency by 15–20% when doubling cores up to 128. Weak scaling efficiency also fell to around 25% in the worst case (i.e., when using a single core as the baseline). Additional benchmarks on Virginia Tech’s AMD-based Tinkercliffs cluster showed that AMD’s power management features (Turbo Core, RAPL) silently altered CPU frequencies—decreasing under full load and increasing when idle—exacerbating poor intra-node scalability. These frequency shifts did not affect inter-node tests, highlighting a unique intra-node performance bottleneck.
Performance Improvement
We re-implemented and optimized the DGLAP evolution solver in C++, achieving a 1.86x speedup on a single core. A hybrid scheduling strategy—static across nodes and dynamic within nodes—reduced idle time by 62%, yielding a 2.46x speedup per node. Intra-node strong scaling efficiency remained high (95-98%) under partial load (e.g., half of cores active), although full loads still triggered CPU frequency drops that limited scalability—an issue not easily mitigated through code. Weak scaling efficiency also improved, reaching approximately 50% in the worst-case scenario (i.e., when using a single core as the baseline).
Contact
Niteya Shah (niteya@vt.edu)
Pi-Yueh Chuang (pchuang@anl.gov)
Wuchun Feng (feng@ct.vt.edu)
Reference
2024 IEEE High Performance Extreme Computing Conference (2024) 1-8