
 This work introduces a Scalable Asynchronous Generative Inverse Problem Solver (SAGIPS) for high-performance computing systems. The resulting workflow utilizes an asynchronous ring-allreduce algorithm to transfer the gradients of a Generative Adverserial Network (GAN) across multiple GPUs. Experiments with a scientific proxy application demonstrate convergence quality comparable to traditional methods and near-linear weak scaling. This novel approach holds the potential to significantly advance methods for solving complex, large-scale inverse problems.
This work introduces a Scalable Asynchronous Generative Inverse Problem Solver (SAGIPS) for high-performance computing systems. The resulting workflow utilizes an asynchronous ring-allreduce algorithm to transfer the gradients of a Generative Adverserial Network (GAN) across multiple GPUs. Experiments with a scientific proxy application demonstrate convergence quality comparable to traditional methods and near-linear weak scaling. This novel approach holds the potential to significantly advance methods for solving complex, large-scale inverse problems.
Background
The goal of the QuantOm collaboration is to analyze nuclear physics scattering data in order to determine the underlying parton distribution functions (PDFs). While the translation from PDFs to scattering data can be simulated, the inverse problem is significantly more challenging. Tackling these kinds of inverse problems is crucial for both contemporary research and various industrial contexts. Given deep learning’s success in addresing similar complex challenges, it’s logical to develop a general-purpose inverse-problem solver using deep learning techniques.
The Science
The core of the proposed inverse problem solver is a Generative Adversarial Network (GAN). The generator proposes candidate parton density functions, which are then fed into a simulation pipeline that converts these predictions into synthetic nuclear scattering events. The discriminator compares these generated events against real experimental data and guides the generator’s learning. Training continues until the discriminator can no longer distinguish synthetic events from actual measurements. At that point, the generator produces parton densities that accurately capture the behavior of quarks and gluons.
The simulation pipeline itself consists of theoretical calculations that translate the generator’s density predictions into nuclear scattering cross sections. A subsequent sampler produces individual scattering events based on these cross sections, and a final module applies experimental effects (e.g. resolution and background contributions) to mirror the conditions under which the real data were collected.
Two major challenges arise when designing this solver:
- Data Volume: The sheer size of the datasets can exceed the memory capacity of a single GPU.
- Computational Load: The multi-stage pipeline demands substantial processing power which may delay the communication between the generator and discriminator.
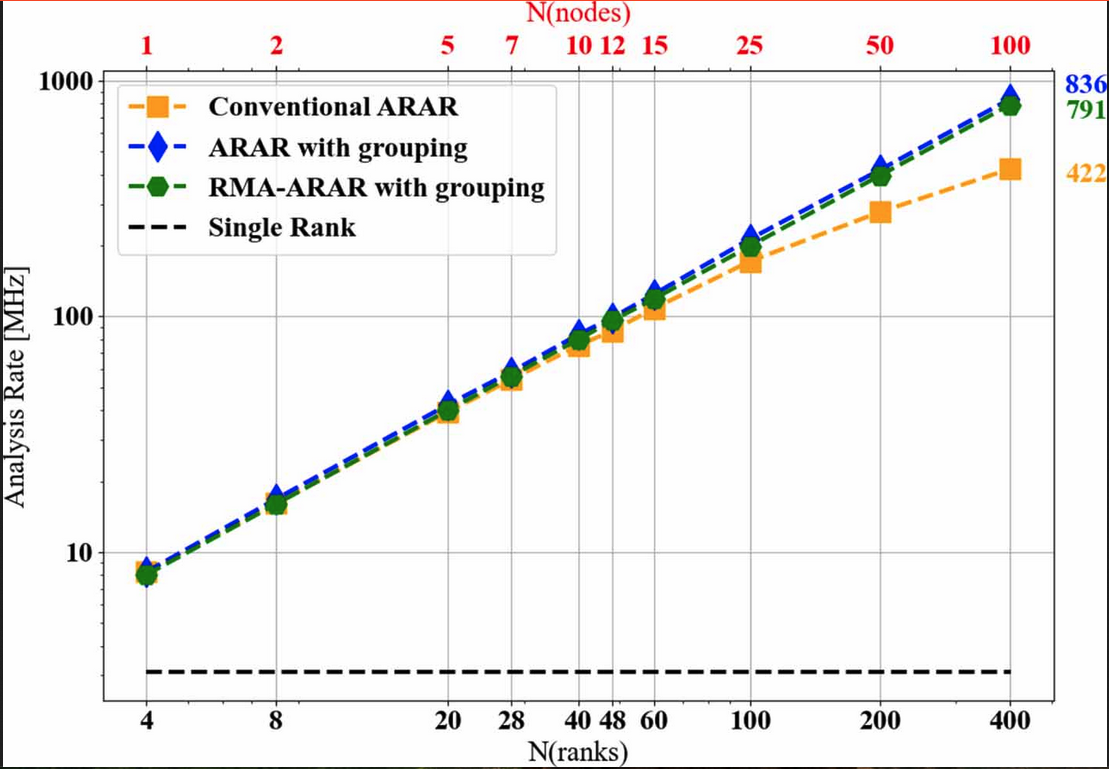
To overcome these hurdles, this work introduces an asynchronous ring–all–reduce algorithm that distributes the generator’s gradient updates across multiple GPUs. Extensive experiments with a toy proxy problem on the Polaris HPC system showed that this distributed training method follows weak linear scaling and is superior to the horovod distributed framework.
This solver is designed to support alternative deep learning or machine learning approaches beyond GANs, offering users greater flexibility.
Contact
Daniel Lersch (dlersch@jlab.org)